

Before a quantum computer can solve a problem, it needs to understand it—and that starts with quantum data loading. This process transforms classical information, be it a molecular state or a handwritten digit, into a quantum-friendly format. Done right, it unlocks the speed and parallelism that make quantum algorithms powerful. Otherwise, it can erase any advantage. As researchers push for deeper circuits, higher accuracy, and larger datasets, quantum data loading is becoming one of the most critical—and competitive—elements in quantum computing.

Quantum data loading is the process of encoding classical data into a quantum computer to facilitate quantum computation. This step is critical as it translates the model of a real-world problem into a format that a quantum computer can process and analyze. The data could take various forms, such as vectors or matrices for quantum algorithms like Harrow-Hassidim-Lloyd (HHL), images for quantum machine learning algorithms, or states describing molecular ground states in quantum chemistry applications. Given the diverse applications and the critical role of this process, optimizing quantum data loading is a primary focus in quantum computing research.
Here’s a quantum data loading example:
Suppose you’re training a quantum machine learning model to recognize handwritten digits from the MNIST dataset. Each image, originally a 28×28 grid of pixel values, must first be transformed into a quantum state that encodes the intensity of each pixel. Using amplitude encoding, these values are normalized and mapped to qubit amplitudes, allowing the quantum computer to hold all pixel information in superposition. Once loaded, the quantum algorithm can process every pixel configuration at the same time.
Traditional approaches to quantum data encoding often rely on methods that scale poorly, requiring an exponential number of gates. These approaches, while intuitive from a classical perspective, fail to represent complex states through entanglement.
A more sophisticated strategy involves the use of Quantum Circuit Born Machines (QCBMs). QCBMs represent a method to learn a quantum circuit that prepares a quantum state mirroring the desired data. Our approach builds upon QCBMs, introducing two innovations: an improved method for learning in variational circuits and a practical implementation that scales to large quantum circuits with up to 30 qubits and 1000 parameters. In some approaches, prepared quantum states are stored in quantum memory, allowing them to be accessed and reused in later stages of computation without repeating the entire loading process.
Addressing the challenges associated with training deep variational circuits, we propose a hierarchical learning method (see arXiv:2311.12929) tailored for QCBMs with a large number of qubits. This approach uses the structure of bitstring measurements and their correlation with the samples they represent. Recognizing that the correlations between the most significant (qu)bits are disproportionately important for smooth distributions, our hierarchical learning methods initiate training with a smaller subset of qubits. The focus here is on a coarse-grained version of the distribution, which then informs the configuration of a larger, more complex circuit.

Newly added qubits are initialized in the |+⟩ state, facilitating even amplitude distribution for bitstrings with identical prefixes, thereby approximating the finer details of the distribution more effectively.

To improve the interpretability of our QCBM's performance, we monitor the total variational (TV) distance between the target distribution and the distribution generated by our model. The TV distance provides a quantitative measure of how closely our quantum model approximates the desired data distribution. This measure is particularly useful for comparing performances across QCBMs of different sizes and configurations, offering insights into the scalability and efficiency of our hierarchical learning approach.
Our technique revolves around the ability to load various distributions into quantum computers with unprecedented accuracy. Traditional methods, such as naive Quantum Circuit Born Machines (QCBM), fall short in terms of precision and efficiency—particularly on large-scale experiments. Our method, however, uses hierarchical learning to achieve remarkable results in loading 1D, 2D, and 3D normal distributions.
The process begins with the iterative loading of a 1D normal distribution. Each iteration refines the distribution's accuracy, gradually aligning it with the desired outcome. This method not only surpasses the capabilities of QCBM but also guarantees a higher fidelity in the representation of quantum states. The final results of this process are not just impressive; they're a testament to the potential of hierarchical learning in quantum data processing.
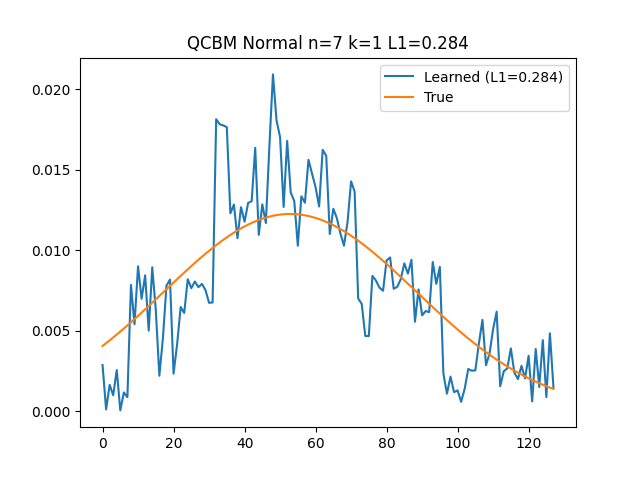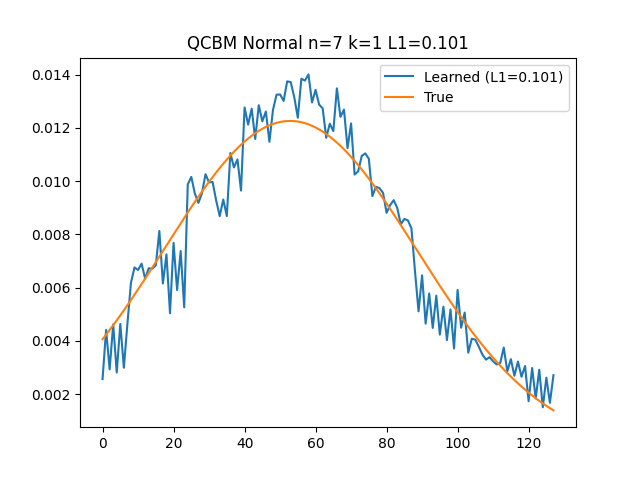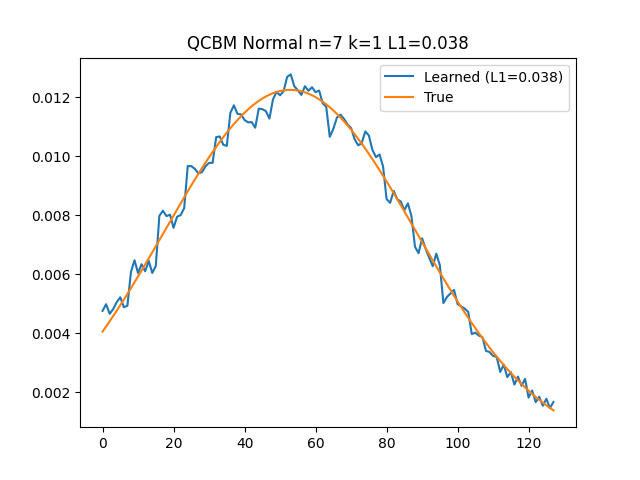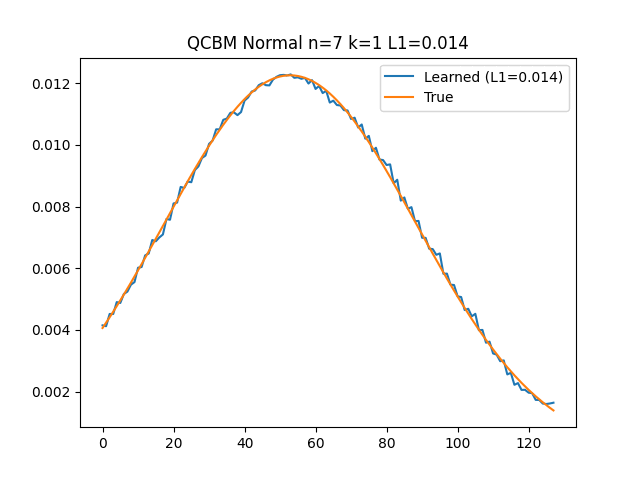
Expanding our technique to 2D and 3D normal distributions further demonstrates its versatility and effectiveness. Through successive iterations, we observed a consistent decrease in loss, and the learned distribution increasingly resembled the target distribution. These experiments, conducted on IBM quantum machines with the collaboration of Q-CTRL, underscore the practicality and scalability of our method. For an in-depth exploration of these experiments, you can take a look at Q-CTRL's blog post.
Our technique can also be applied to the loading of image data into quantum systems. We experimented with the MNIST dataset, using just 10 qubits, and achieved results that far surpass the current state-of-the-art. Not only did we manage to obtain 2x better accuracy, but we also reduced the number of required entangling gates by half. The comparison between the loaded and original MNIST images clearly shows the efficacy of our approach. We plan to release a comprehensive dataset of MNIST images loaded using our technique, which can serve as a valuable resource for further research.

Efficient quantum data loading is key to the execution of complex algorithms and the realization of quantum advantage. Our technique is a leap forward in this domain, offering a scalable and accurate method for data loading.

By addressing the challenge of quantum data loading, we not only facilitate the practical application of quantum computing across various fields but also pave the way for exponential speedups in fundamental operations such as linear algebra, matrix multiplication, and vector products. The potential for our data loading technique to serve as a cornerstone for future advancements in quantum computing is immense.
Our quantum data loader is available through BlueQubit's Team tier. As we continue to refine and expand our techniques, we remain committed to contributing to the collective knowledge and capabilities of the quantum computing community.
Quantum data loading faces several challenges, including the exponential cost of mapping large classical datasets onto qubits, noisy hardware that can degrade data fidelity, and the limited number of qubits available on current devices. Moreover, some loading schemes require complex entanglement patterns or deep circuits, which are difficult to implement without introducing significant errors.
Quantum data loading allows for efficient quantum state preparation, providing algorithms with well-prepared states that minimize setup overhead and accelerate quantum computations. By using optimized encoding schemes, the algorithm can access data in superposition, letting it process multiple inputs at the same time. This can lead to polynomial or exponential speedups compared to classical approaches, depending on the problem.
There are several optimization techniques used for encoding classical data into qubits. These include:
Amplitude encoding: represents data in the amplitudes of a quantum state for compact storage.
Basis encoding: maps binary data directly to qubit states for simple implementation.
Angle encoding: encodes values into rotation angles of qubits for parameterized circuits.
Hybrid pre-processing: uses classical dimensionality reduction before loading data to reduce qubit requirements.
QRAM-based approaches: for rapid access to large datasets without loading them element-by-element.
The Holevo bound states that n qubits can carry at most n bits of classical information when measured, regardless of how much is encoded in their quantum state. This means that while quantum states can represent exponentially large datasets in superposition, the amount of extractable classical information is fundamentally limited. As a result, quantum data loading is most effective for algorithms that use the data internally in quantum form—not for retrieving the entire dataset back in classical form.


